Evaluator Models
AutoEval models for evaluation tasks
AutoEval ships with small language models (SLMs) optimized for evaluation tasks. The Metrics section lists all out-of-the-box metrics available on the platform.
In addition, if you need to design your own metric, you can fine-tune LastMile's alBERTa 🍁 base model to build a custom evaluator.
alBERTa 🍁
alBERTa is a 400M parameter BERT model that has been trained for NLI tasks and optimized for evaluation workfloads. It is particularly good at framing questions in the premise/hypothesis/entailment formulation, and returns a numeric probability score (0->1), which makes it particularly well-suited for computing metrics.
Key value props:
- small -- 400M parameters small
- fast -- can run inference on CPU in < 300ms
- customizable -- fine-tune for custom evaluation tasks
- self-hostable -- available for VPC deployment
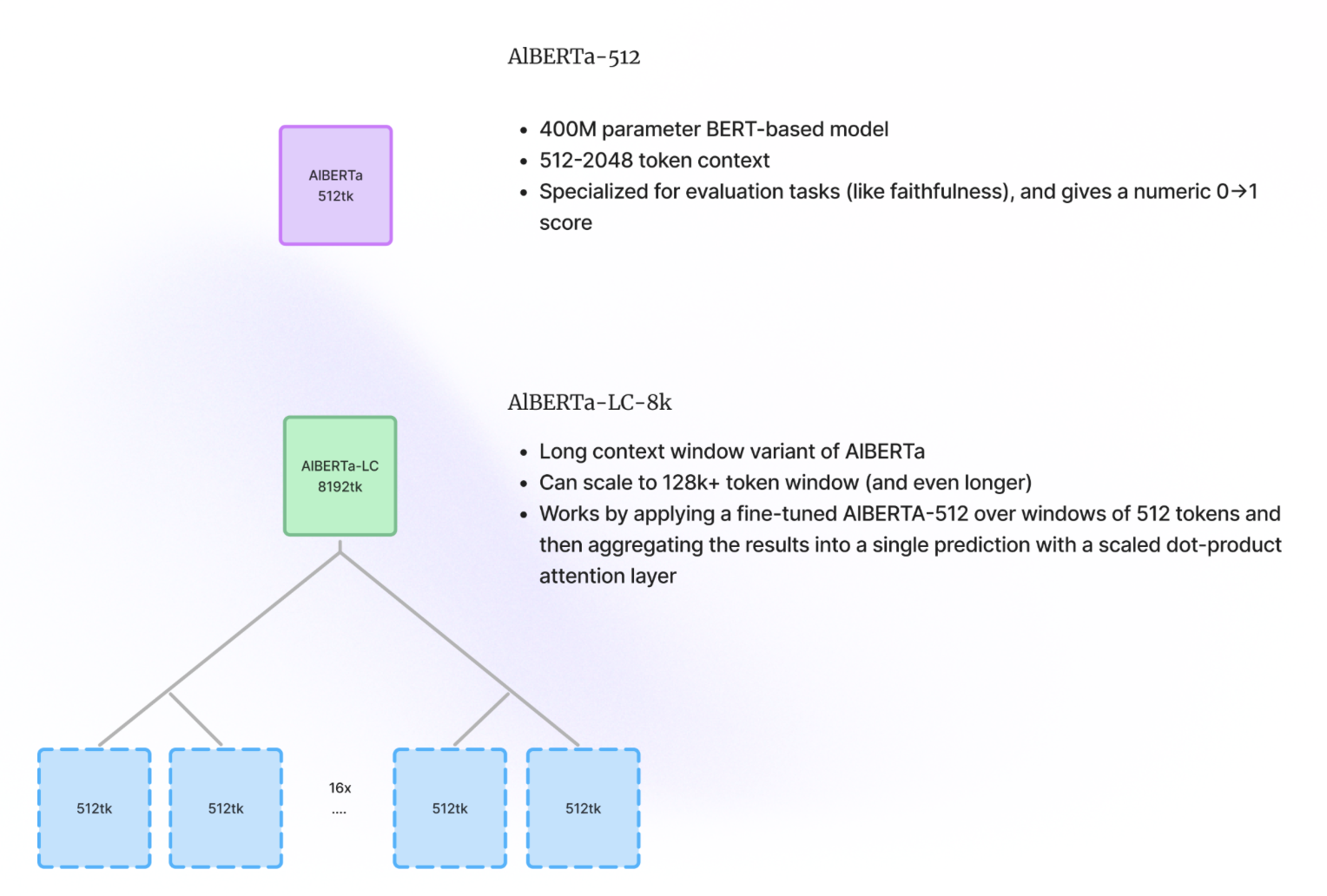
There are two variants in the alBERTa model family:
| model | context window | latency | fine-tune | description |
|---|---|---|---|---|
| alBERTa-512 | 512 tokens | <10ms | ✅ | 512-token context variant, available for fine-tuning, and specialized for evaluation tasks (e.g. faithfulness) |
| alBERTa-LC-8k | 8192 tokens | <400ms | Long-context window variant that can scale to 128k+ tokens using a scaled dot-product attention layer |
Usage Guide
Running evals is possible both from the Model Console dashboard as well as the API.
Console
You can run a one-off evaluation from the model playground. Click any model in the Model Console.
Click Run Model (the play button) to compute a score on some provided data.

Depending on what metric the model calculates, it will accept different input fields. For example, Faithfulness measures the faithfulness of the output to the ground_truth (i.e. context provided)
given the input. On the other hand, Summarization measures the quality of the output summary given the input (no ground_truth needed).
API
Reference models by their name or id (both are available from the console. For example, the Faithfulness model can be referenced by its name, or its id cm2plr07q000ipkr4o8qhj4oe).
- python
- node.js
from lastmile.lib.auto_eval import AutoEval, Metric
import pandas as pd
client = AutoEval(api_token="api_token_if_LASTMILE_API_TOKEN_not_set")
query = "Where did the author grow up?"
expected_response = "England"
llm_response = "France"
# Evaluate data in a dataframe
data_result_df = client.evaluate_data(
data=pd.DataFrame({
"input": [query],
"output": [llm_response],
"ground_truth": [expected_response]
}),
metrics=[Metric(name="Faithfulness")]
)
# Evaluate data in a Dataset
dataset_result_df = client.evaluate_dataset(
dataset_id=dataset_id,
metrics=[Metric(id="cm2plr07q000ipkr4o8qhj4oe"), Metric(name="Summarization")]
)
import { AutoEval, Metric } from "lastmile/lib/auto_eval";
const client = new AutoEval({
apiKey: "api_token_if_LASTMILE_API_TOKEN_not_set",
});
const query = "Where did the author grow up?";
const expectedResponse = "England";
const llmResponse = "France";
// Evaluate data using a direct array of DataRows
const dataResult = await client.evaluateData(
[
{
input: query,
output: llmResponse,
ground_truth: expectedResponse,
},
],
[{ name: "Faithfulness" }] // Metrics
);
console.table(dataResult);
// Evaluate data in a dataset
const datasetId = "your_dataset_id"; // Replace with your dataset ID
const datasetResult = await client.evaluateDataset(
datasetId,
/*metrics*/ [
{ id: "cm2plr07q000ipkr4o8qhj4oe" }, // Metric by ID
{ name: "Summarization" }, // Metric by name
]
);
console.table(datasetResult);
You can reference any metric by its name as it appears in the Model Console. Accepted values include:
Metric(name="Faithfulness")Metric(name="Relevance")Metric(name="Summarization")Metric(name="Toxicity")Metric(name="Answer Correctness")
You can use the same method to run inference on fine-tuned evaluator models. Simply refer to them by their name or id.
Since alBERTa 🍁 models are small and fast, you can run them online as guardrails. Learn more or follow this in-depth guide.