Evaluation Metrics
Out-of-the-box metrics for common AI applications
This section covers metrics available out-of-the-box in AutoEval. You can also fine-tune your own metric.
All evaluators work on some combination of the following properties:
input: Input to the application (e.g. a user question for a Q&A system)output: The response generated by the application (e.g. LLM generation)ground_truth: Factual data, either the ideal correct response, or context used to generate the output (e.g. data retrieved from a vector DB)
Running evals is possible both from the Model Console dashboard as well as the API/SDKs.
You can run a one-off evaluation from the model playground. Open any metric in the Model Console,
and click Run Model (the play button) to compute a score on some provided data.

Hallucination Detection (Faithfulness)
Definition
Given an input, measures the faithfulness of an LLM-generated output to the provided context or ground truth. It returns a 0->1 probability score which answers “To what extent is the generated answer faithful to the provided context without introducing unsupported information?”
It is particularly useful in RAG applications, and a good proxy for hallucination detection. The task is a Natural Language Inference (NLI) task that measures if the output can be logically inferred from the context and input.
Required fields:
input- e.g. user queryoutput- LLM responseground_truth- context used to generate output
The LastMile faithfulness evaluator is able to identify subtle mistakes that an LLM might make. For example, in a customer service assistant, for a "What is the customer service phone number?" query, if the LLM even subtly misses the number (e.g. 123-546-7890 instead of 123-456-7890), the faithfulness detector will catch it. Give it a try!
Usage Guide
- python
- node.js
from lastmile.lib.auto_eval import AutoEval, BuiltinMetrics
import pandas as pd
client = AutoEval(api_token="api_token_if_LASTMILE_API_TOKEN_not_set")
query = "What is Albert Einstein famous for?"
context_retrieved = """
Albert Einstein was a German-born theoretical physicist who developed
the theory of relativity, one of the two pillars of modern physics. His
work is also known for its influence on the philosophy of science. He is
best known to the general public for his mass-energy equivalence formula
E = mc², which has been dubbed 'the world's most famous equation'. He
received the 1921 Nobel Prize in Physics 'for his services to theoretical
physics, and especially for his discovery of the law of the photoelectric
effect', a pivotal step in the development of quantum theory."""
llm_response = "Albert Einstein is famous for the formula E = mc² and Brownian motion."
eval_result = client.evaluate_data(
data=pd.DataFrame({
"input": [query],
"output": [llm_response],
"ground_truth": [context_retrieved]
}),
metrics=[BuiltinMetrics.FAITHFULNESS]
)
print(eval_result)
import { AutoEval, BuiltinMetrics } from "lastmile/lib/auto_eval";
const client = new AutoEval({
apiKey: "api_token_if_LASTMILE_API_TOKEN_not_set",
});
const query = "What is Albert Einstein famous for?";
const contextRetrieved = `
Albert Einstein was a German-born theoretical physicist who developed
the theory of relativity, one of the two pillars of modern physics. His
work is also known for its influence on the philosophy of science. He is
best known to the general public for his mass-energy equivalence formula
E = mc², which has been dubbed 'the world's most famous equation'. He
received the 1921 Nobel Prize in Physics 'for his services to theoretical
physics, and especially for his discovery of the law of the photoelectric
effect', a pivotal step in the development of quantum theory.`;
const llmResponse = "Albert Einstein is famous for the formula E = mc² and Brownian motion.";
// Evaluate data using the FAITHFULNESS metric
const evalResult = await client.evaluateData(
[
{
"input": query,
"output": llmResponse,
"ground_truth": contextRetrieved,
},
],
[BuiltinMetrics.FAITHFULNESS]
);
console.table(evalResult);
Explanation
The faithfulness score of 0.66 suggests that the LLM-generated response is only partially faithful to the retrieved context. While it correctly mentions Einstein's famous equation, E = mc², it also includes information about Brownian motion, which is not present in the context. The inclusion of this additional information likely contributed to the lower score, indicating that the LLM relied on its own knowledge beyond the given context.
Summarization Score
The Summarization evaluator measures the quality of an LLM-generated summary compared to the source document. It aims to assess how well the summary captures the essential information and main ideas of the source document. It returns a 0->1 score which answers: "To what extent does the generated summary capture the essential information from the source document?"
Required fields:
output- LLM generated summaryground_truth- source document (e.g. context used to generate output)
Usage Guide
- python
- node.js
from lastmile.lib.auto_eval import AutoEval, BuiltinMetrics
import pandas as pd
client = AutoEval(api_token="api_token_if_LASTMILE_API_TOKEN_not_set")
source_document = """
Albert Einstein was a German-born theoretical physicist who developed
the theory of relativity, one of the two pillars of modern physics. His work
is also known for its influence on the philosophy of science. He is best known
to the general public for his mass-energy equivalence formula E = mc²,
which has been dubbed 'the world's most famous equation'. Einstein received
the 1921 Nobel Prize in Physics 'for his services to theoretical physics, and
especially for his discovery of the law of the photoelectric effect', a
pivotal step in the development of quantum theory. In his later years,
Einstein focused on unified field theory and became increasingly isolated
from the mainstream of modern physics."""
llm_summary = """
Albert Einstein, a German-born physicist, developed the theory of
relativity and the famous equation E = mc². He won the 1921 Nobel Prize
in Physics for his work on the photoelectric effect, contributing to
quantum theory. Later, he worked on unified field theory."""
eval_result = client.evaluate_data(
data=pd.DataFrame({
"output": [llm_summary],
"ground_truth": [source_document]
}),
metrics=[BuiltinMetrics.SUMMARIZATION]
)
print(eval_result)
import { AutoEval, BuiltinMetrics } from "lastmile/lib/auto_eval";
const client = new AutoEval({
apiKey: "api_token_if_LASTMILE_API_TOKEN_not_set",
});
const sourceDocument = `
Albert Einstein was a German-born theoretical physicist who developed
the theory of relativity, one of the two pillars of modern physics. His work
is also known for its influence on the philosophy of science. He is best known
to the general public for his mass-energy equivalence formula E = mc²,
which has been dubbed 'the world's most famous equation'. Einstein received
the 1921 Nobel Prize in Physics 'for his services to theoretical physics, and
especially for his discovery of the law of the photoelectric effect', a
pivotal step in the development of quantum theory. In his later years,
Einstein focused on unified field theory and became increasingly isolated
from the mainstream of modern physics.`;
const llmSummary = `
Albert Einstein, a German-born physicist, developed the theory of
relativity and the famous equation E = mc². He won the 1921 Nobel Prize
in Physics for his work on the photoelectric effect, contributing to
quantum theory. Later, he worked on unified field theory.`;
// Evaluate data using the SUMMARIZATION metric
const evalResult = await client.evaluateData(
[
{
"output": llmSummary,
"ground_truth": sourceDocument,
},
],
[BuiltinMetrics.SUMMARIZATION]
);
console.table(evalResult);
Explanation
The summarization score of 0.88 indicates the summary effectively captures key points about Einstein, including his German origin, development of relativity theory, E = mc² equation, 1921 Nobel Prize for the photoelectric effect, and work on unified field theory. It successfully condenses essential information while maintaining accuracy. The score isn't perfect, likely due to omitting Einstein's influence on philosophy of science and his later isolation from mainstream physics.
Relevance
The Relevance evaluator measures the semantic similarity between two strings. It can be used to compare
- response relevancy -- how relevant is the generated output to the input prompt?
- context relevancy -- how relevant is the generated output to the context retrieved?
- answer equivalence -- how similar is the generated output to a ground truth expected response?
Required fields:
input- one string to compare (e.g. input query)output- second string to compare (e.g. generated response)
Usage Guide
- python
- node.js
from lastmile.lib.auto_eval import AutoEval, BuiltinMetrics
import pandas as pd
client = AutoEval(api_token="api_token_if_LASTMILE_API_TOKEN_not_set")
llm_response ="""
Albert Einstein revolutionized physics with his theory of relativity.
He proposed that space and time are interconnected and that the speed of
light is constant in all reference frames. His famous equation E = mc²
showed that mass and energy are equivalent. Einstein's work on the
photoelectric effect contributed to the development of quantum theory,
earning him the Nobel Prize in Physics."""
expected_response = """
Albert Einstein transformed our understanding of the universe with his
groundbreaking theories. His special and general theories of relativity
redefined concepts of space, time, and gravity. Einstein's equation E = mc²
revealed the fundamental relationship between mass and energy. His
explanation of the photoelectric effect was crucial to the emergence of
quantum physics, for which he received the Nobel Prize. Throughout his career,
Einstein's innovative thinking and scientific contributions reshaped the
field of physics."""
eval_result = client.evaluate_data(
data=pd.DataFrame({
"input": [expected_response],
"output": [llm_response],
}),
metrics=[BuiltinMetrics.RELEVANCE]
)
print(eval_result)
import { AutoEval, BuiltinMetrics } from "lastmile/lib/auto_eval";
const client = new AutoEval({
apiKey: "api_token_if_LASTMILE_API_TOKEN_not_set",
});
const expectedResponse = `
Albert Einstein transformed our understanding of the universe with his
groundbreaking theories. His special and general theories of relativity
redefined concepts of space, time, and gravity. Einstein's equation E = mc²
revealed the fundamental relationship between mass and energy. His
explanation of the photoelectric effect was crucial to the emergence of
quantum physics, for which he received the Nobel Prize. Throughout his career,
Einstein's innovative thinking and scientific contributions reshaped the
field of physics.`;
const llmResponse = `
Albert Einstein revolutionized physics with his theory of relativity.
He proposed that space and time are interconnected and that the speed of
light is constant in all reference frames. His famous equation E = mc²
showed that mass and energy are equivalent. Einstein's work on the
photoelectric effect contributed to the development of quantum theory,
earning him the Nobel Prize in Physics.`;
const evalResult = await client.evaluateData(
[
{
"input": expectedResponse,
"output": llmResponse,
},
],
[BuiltinMetrics.RELEVANCE]
);
console.table(evalResult);
Explanation
The relevance score of 0.94 indicates high alignment between the LLM-generated response and the expected output. Both texts cover Einstein's key contributions: the theory of relativity, E = mc², and the photoelectric effect. The score isn't perfect, as the LLM response omits mentions of general relativity and Einstein's broader impact on physics. However, it adds relevant details about light's constant speed. Overall, the high score reflects strong topical relevance and accurate conveyance of Einstein's main scientific achievements.
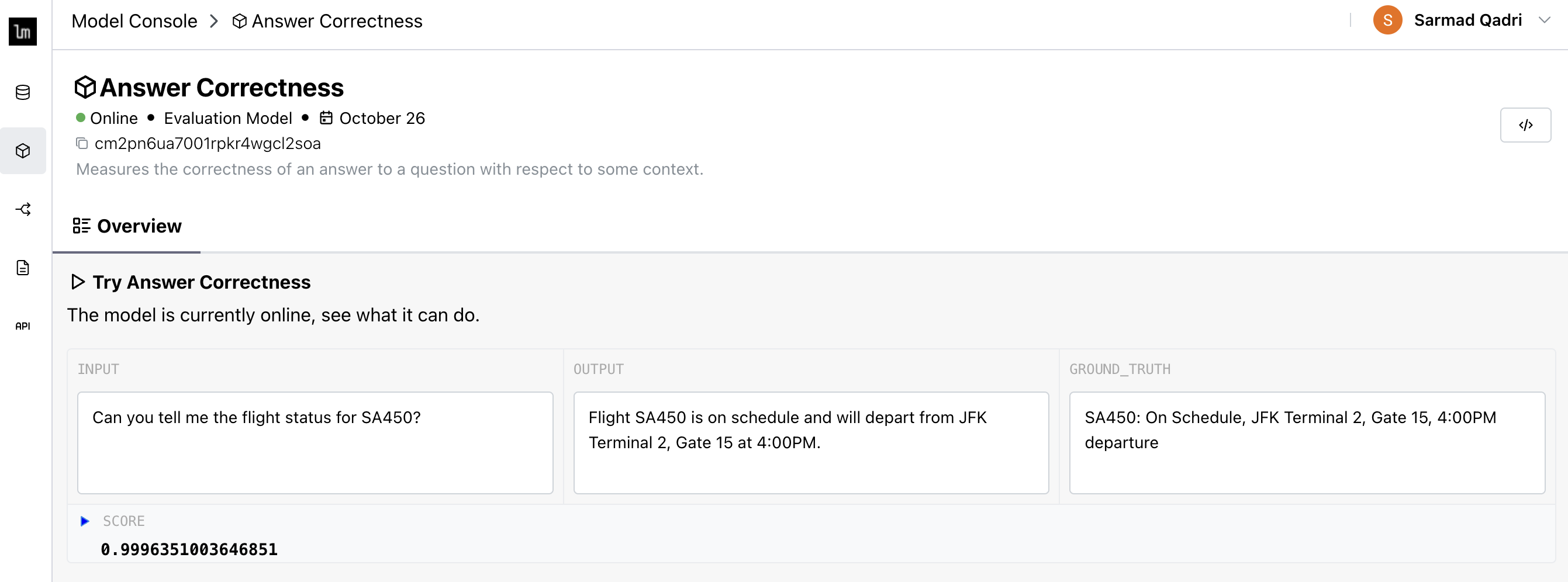
Answer Correctness
The Answer Correctness evaluator is a binary measure of whether an LLM-generated response answers a user query based on the retrieved context. It aims to evaluate the accuracy and completeness of the answer in relation to the provided information. It returns a 0->1 score which answers: "Does the LLM-generated response correctly and completely answer the user query based on the retrieved context?"
Required fields:
input- Input promptoutput- LLM responseground_truth- Ideal response or correct answer
Usage Guide
- python
- node.js
from lastmile.lib.auto_eval import AutoEval, BuiltinMetrics
import pandas as pd
client = AutoEval(api_token="api_token_if_LASTMILE_API_TOKEN_not_set")
query = "Can you tell me the flight status for SA450?"
context_retrieved = "Flight SA450 is on schedule and will depart from JFK Terminal 2, Gate 15 at 4:00PM."
llm_response = "SA450: On Schedule, JFK Terminal 2, Gate 15, 4:00PM departure"
eval_result = client.evaluate_data(
data=pd.DataFrame({
"input": [query],
"output": [llm_response],
"ground_truth": [context_retrieved]
}),
metrics=[BuiltinMetrics.ANSWER_CORRECTNESS]
)
print(eval_result)
import { AutoEval, BuiltinMetrics } from "lastmile/lib/auto_eval";
const client = new AutoEval({
apiKey: "api_token_if_LASTMILE_API_TOKEN_not_set",
});
const query = "Can you tell me the flight status for SA450?";
const contextRetrieved = "Flight SA450 is on schedule and will depart from JFK Terminal 2, Gate 15 at 4:00PM.";
const llmResponse = "SA450: On Schedule, JFK Terminal 2, Gate 15, 4:00PM departure";
const evalResult = await client.evaluateData(
[
{
"input": query,
"output": llmResponse,
"ground_truth": contextRetrieved
},
],
[BuiltinMetrics.ANSWER_CORRECTNESS]
);
console.table(evalResult);
Explanation
The above yields a score of 0.999, indicating the LLM response fully and accurately answers the query based on the context.
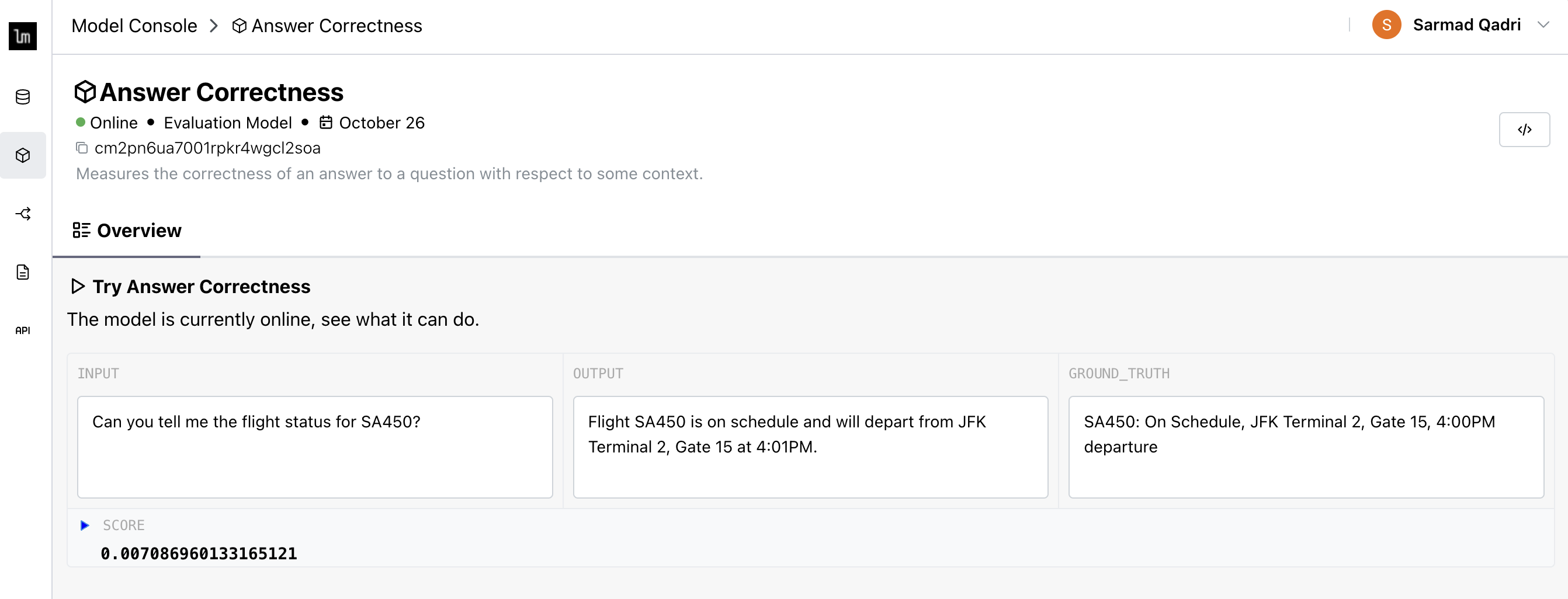
Now try changing the generated response time from 4:00pm to 4:01pm, a very subtle change.
Doing so yields a score of 0.007, as expected.
Output Quality Evaluators
In addition to the above, there are a few metrics for response quality which can be helpful. We list them here for completeness, but don't provide them in AutoEval since they are easy to calculate on your own (see Usage Guide below):
Exact Match
Exact Match is a fancy way of saying string equals. It assesses whether an LLM-generated response is identical to a reference text. It provides a binary score indicating perfect string matching. The Exact Match score answers: "Is the LLM-generated response exactly the same as the reference text?"
BLEU
The BLEU (Bilingual Evaluation Understudy) score measures how similar a machine-generated text is to a reference text. It does this by comparing overlapping words and phrases, including sequences of words called n-grams. The BLEU score answers: _"How closely does the LLM-generated text match the reference text in terms of word and phrase usage?" Learn more.
ROUGE
The ROUGE (Recall-Oriented Understudy for Gisting Evaluation) score measures how well a machine-generated summary captures the content of a reference summary. Unlike BLEU, which focuses on precision, ROUGE emphasizes recall, assessing how much of the reference content is present in the generated text. The ROUGE score answers: "How well does the LLM-generated summary cover the key information from the reference summary?" Learn more.
Usage Guide
- pip
pip install nltk rouge-score
- python
from nltk.translate.bleu_score import sentence_bleu
from rouge_score import rouge_scorer
import numpy as np
def calculate_bleu(reference, hypothesis):
"""
Calculate BLEU score for a single reference and hypothesis.
:param reference: List of tokens for the reference sentence.
:param hypothesis: List of tokens for the hypothesis sentence.
:return: BLEU score.
"""
return sentence_bleu([reference], hypothesis)
def calculate_rouge(reference, hypothesis):
"""
Calculate ROUGE scores for a single reference and hypothesis.
:param reference: Reference sentence as a string.
:param hypothesis: Hypothesis sentence as a string.
:return: Dictionary with ROUGE-1, ROUGE-2, and ROUGE-L scores.
"""
scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True)
scores = scorer.score(reference, hypothesis)
return {key: value.fmeasure for key, value in scores.items()}
def calculate_exact_match(reference, hypothesis):
"""
Calculate exact match score for a single reference and hypothesis.
:param reference: Reference sentence as a string.
:param hypothesis: Hypothesis sentence as a string.
:return: Exact match score (1.0 if exact match, 0.0 otherwise).
"""
return 1.0 if reference.strip() == hypothesis.strip() else 0.0
Examples
- BLEU
- ROUGE
- Exact Match
llm_response = """
Einstein developed the theory of relativity, which changed
our understanding of space and time."""
ground_truth = """
Einstein created the theory of relativity that revolutionized
our view of space and time."""
bleu_score = calculate_bleu(
ground_truth,
llm_response
)
Explanation: The BLEU Score of 0.4 shows moderate similarity between the texts. Both convey the core idea about Einstein's theory of relativity, but differ in specific wording (e.g., "developed" vs. "created"). This score reflects BLEU's sensitivity to exact word matches and order, highlighting why it should be used alongside other metrics for comprehensive evaluation.
llm_response = """
Einstein's theory of relativity revolutionized physics by unifying space and time.
It introduced the concept of spacetime and showed that massive objects can warp it.
The theory also led to the famous equation E=mc², relating mass and energy."""
ground_truth = """
Einstein's theory of relativity transformed our understanding of the universe.
It combined space and time into a single continuum called spacetime, which can be
distorted by mass and energy. The theory's most famous outcome is the equation E=mc²,
demonstrating the equivalence of mass and energy."""
rouge_scores = calculate_rouge(
ground_truth,
llm_response
)
Explanation: The ROUGE1 Score of 0.56 indicates moderate content overlap between the generated and reference summaries. Both capture key aspects of Einstein's theory of relativity, including the unification of space and time, spacetime concept, and the E=mc² equation. However, the score suggests some differences in coverage or phrasing. This demonstrates how ROUGE evaluates summary quality based on shared content, balancing similarities and variations in expression.
llm_response = "E = mc^2 is Einstein's famous equation relating energy and mass."
ground_truth = "E = mc^2 is Einstein's famous equation relating energy and mass."
exact_match_score = calculate_exact_match(
ground_truth,
llm_response
)
Explanation: The Exact Match score of 1 indicates the LLM-generated response perfectly matches the reference text. This score is useful for verifying precise reproduction of expected outputs.
Safety Evaluators
Safety Evaluators assess the appropriateness and potential harm of LLM-generated content.
Toxicity
The Toxicity evaluator assesses whether an LLM-generated response contains toxic content. It aims to identify harmful, offensive, or inappropriate elements in the generated text. The Toxicity score answers: "Does the LLM-generated response contain any form of toxic content?"
You can also use the Toxicity evaluator to measure input toxicity.
Required fields:
output- LLM response to assess toxicity for
Usage Guide
- python
- node.js
from lastmile.lib.auto_eval import AutoEval, BuiltinMetrics
import pandas as pd
client = AutoEval(api_token="api_token_if_LASTMILE_API_TOKEN_not_set")
eval_result = client.evaluate_data(
data=pd.DataFrame({
"output": ["This is the worst airline I've ever flown with. You've lost my bags!"],
}),
metrics=[BuiltinMetrics.TOXICITY]
)
print(eval_result)
import { AutoEval, BuiltinMetrics } from "lastmile/lib/auto_eval";
const client = new AutoEval({
apiKey: "api_token_if_LASTMILE_API_TOKEN_not_set",
});
const evalResult = await client.evaluateData(
[
{
"output": "This is the worst airline I've ever flown with. You've lost my bags!",
},
],
[BuiltinMetrics.TOXICITY]
);
console.table(evalResult);
Don't see a metric that perfectly fits your use case? Design your own with the fine-tuning service, or get in touch!