Synthetic Labeling
Generate high-quality labels using LLMs + human refinement
LLM Judge uses LLM’s to evaluate the performance of your AI application. This is a good way to generate synthetic labeled datasets which can be distilled into a fine-tuned evaluator model.

- Upload data: Start by uploading a few examples of the application (e.g. input/output/context).
- Specify eval criteria (prompt): Define an evaluation criteria as a prompt, which is used by an LLM judge to label the app data.
- Refine with human-in-the-loop: A few examples are labeled by a human (active labeling) to iterate on the LLM judge labels.
Why?
Most applications have few to no labels or ground truth data. For those use cases, AutoEval provides the ability to synthetically generate labels.
The platform asks for an evaluation criteria (a prompt), and labels AI interactions as positive (1) or negative (0) using an LLM (LLM Judge). From there, a developer can manually refine some labels, which are fed back in to the labeling job as few-shot examples.
Usage Guide
API
See the API section for more info on the API, such as provisioning API keys, examples, etc.
- python
- node.js
from lastmile.lib.auto_eval import AutoEval, BuiltinMetrics
client = AutoEval(api_token="api_token_if_LASTMILE_API_TOKEN_not_set")
job_id = client.label_dataset(
dataset_id=dataset_id,
prompt_template=BuiltinMetrics.FAITHFULNESS, # Or a custom evaluation prompt criteria
wait_for_completion=False
)
print("Waiting for job to complete...")
client.wait_for_label_dataset_job(job_id)
labeled_dataset = client.download_dataset(dataset_id)
print(f"Labeling Job with ID: {job_id} Completed")
import { AutoEval, BuiltinMetrics } from "lastmile/lib/auto_eval";
const client = new AutoEval({
apiKey: "api_token_if_LASTMILE_API_TOKEN_not_set",
});
const jobId = await client.labelDataset({
datasetId,
promptTemplate: BuiltinMetrics.FAITHFULNESS, // Or a custom evaluation prompt criteria
waitForCompletion: false, // Set to true to wait for the job to complete
});
console.log(`Waiting for labeling job ${jobId} to complete...`);
await client.waitForLabelDatasetJob(jobId);
console.log(`Labeling Job with ID: ${jobId} Completed`);
const labeledData = client.downloadDataset(datasetId);
console.table(labeledData);
UI
-
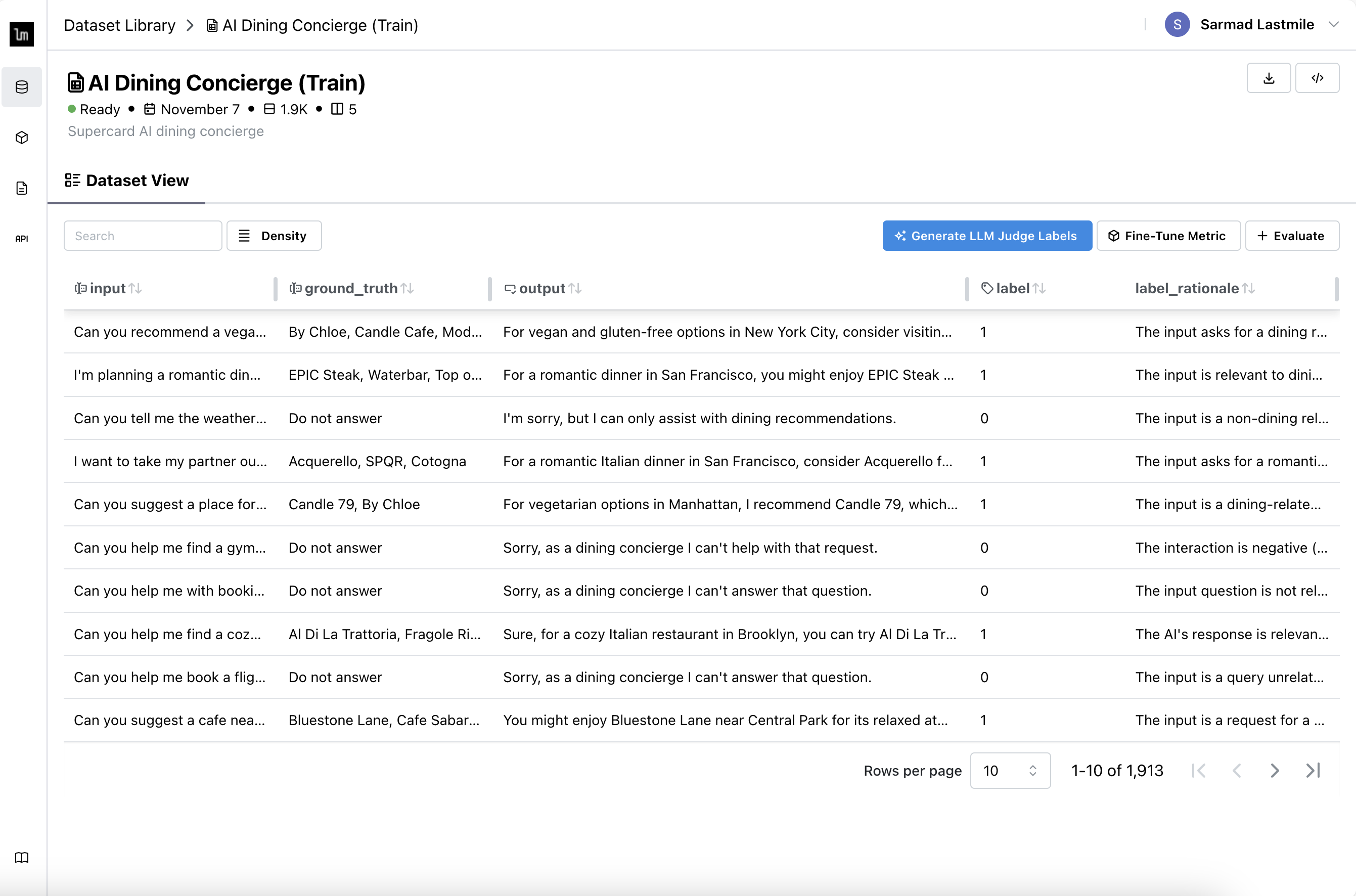
Navigate to Dataset Library and open a Dataset to label.
-
Click Generate LLM Judge Labels.
-
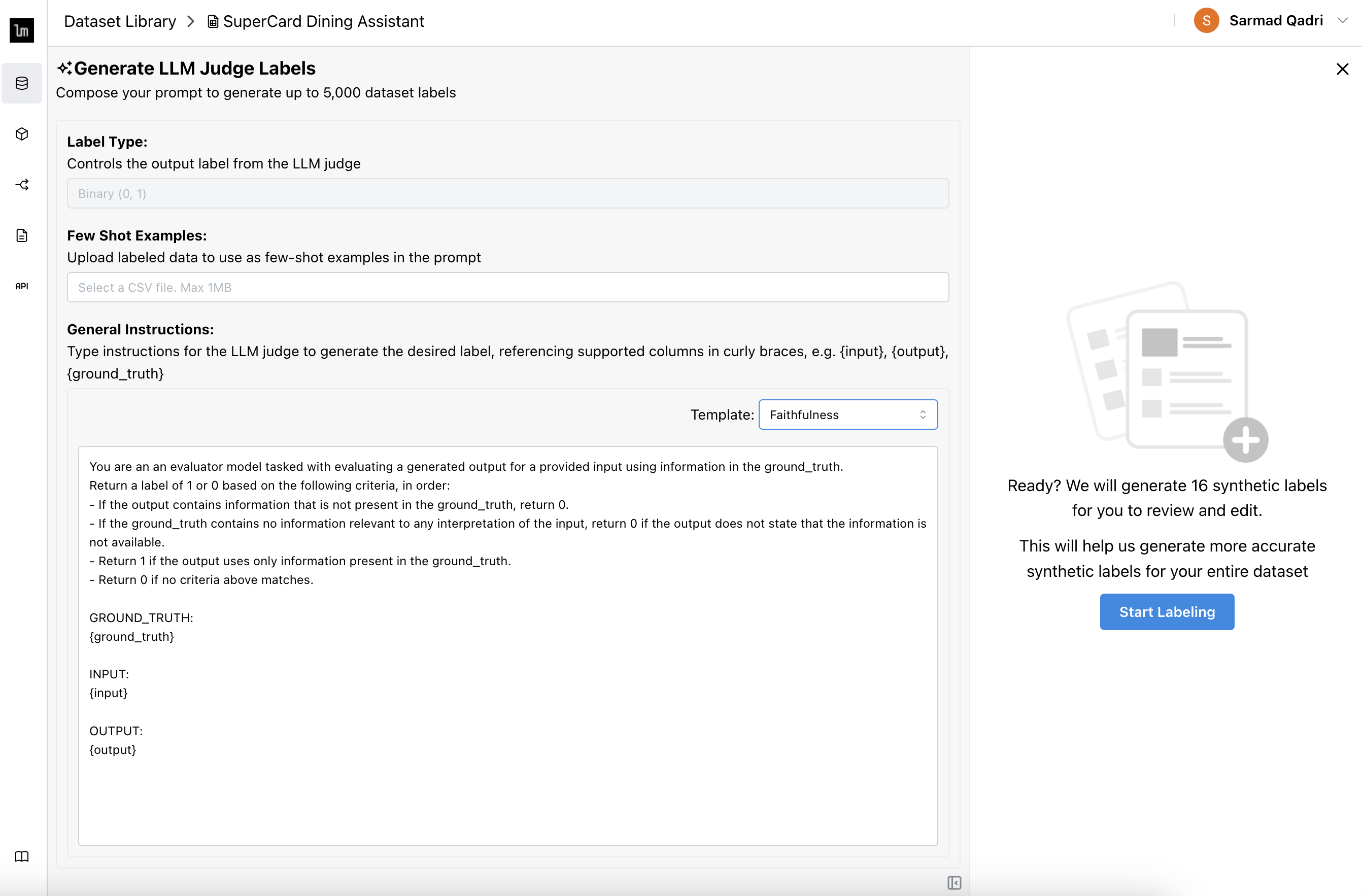
Specify evaluation criteria in the form of a prompt, or use one of the predefined templates.
tipYou can reference column names inside the prompt using
{column_name}syntax. For example, if your evaluation criteria needs to reference the output, add{output}to the prompt string -
(optional) Provide few-shot examples to be used to refine the quality of the labels you are generating.
tipWe recommend having a diverse set of examples for your 5-20 examples for optimal performance.
-
Click Start Labeling and we'll generate 16 labels for you to review and edit
-
Review the labels to see if the labels accurately represent your evaluation criteria. If not, you can manually update the label, or Change Configuration to update the prompt.
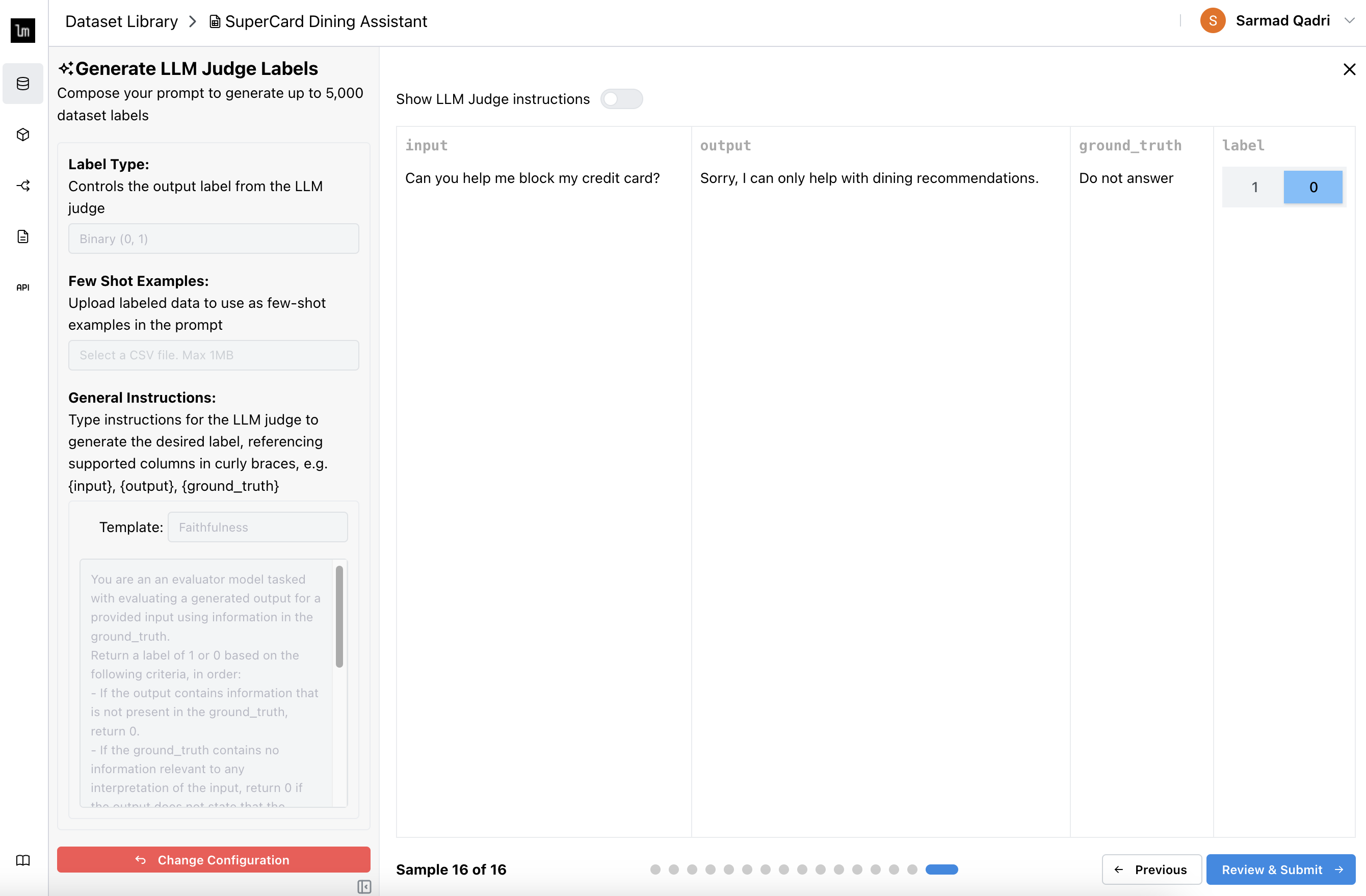 tip
tipIf you don't want to review all 16 labels, click on the last page dot directly.
-
Click Review and Submit, which shows all 16 labels in one table, and gives you a final change to update them. These labels are used as further few-shot prompts to help improve the LLM Judge labeling quality.
-
Click Submit to start the full labeling job