Developer quickstart
Let's get you started with AutoEval
The AutoEval platform is accessible both via UI and API, and provides LLM judge labeling, evaluator model fine-tuning, and inference for evals and guardrails. It is the only service to let you design custom metrics by fine-tuning evaluator models.
Let's walk you through the basics of the platform.
Account Setup
First, you'll need a LastMile AI token to get started.
- Sign up for a free LastMile AI account
- Generate an API key in the dashboard
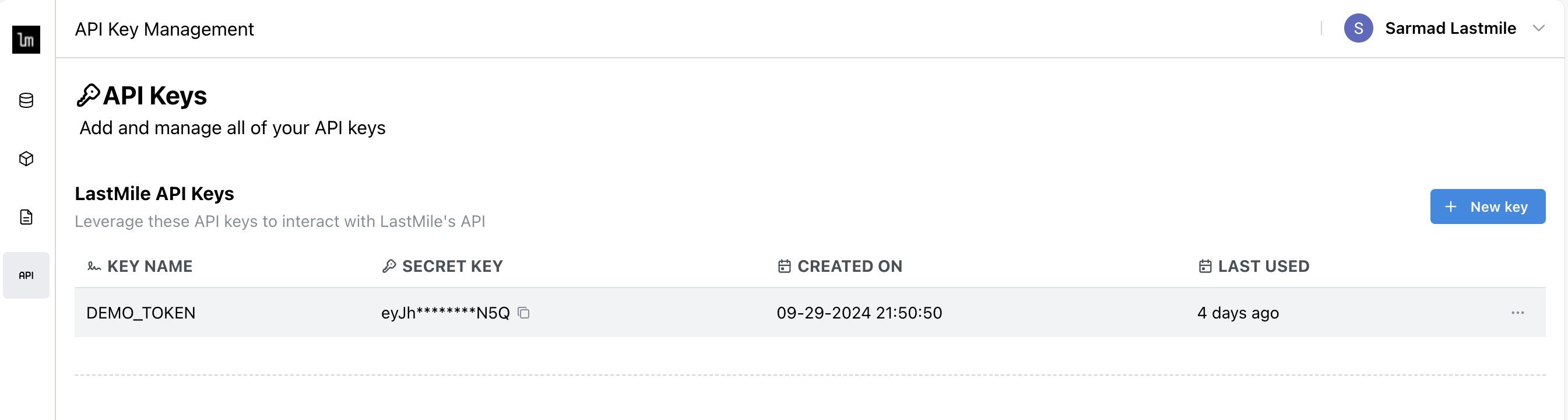
Set API Key
Export the API key you generated as an environment variable. Alternatively, you can also pass it directly into the Lastmile client.
export LASTMILE_API_TOKEN="your_api_key"
Run your first Evals
Let's evaluate an AI application interaction now. All interactions have some combination of:
input: Input to the application (e.g. a user question for a Q&A system)output: The response generated by the application (e.g. LLM generation)ground_truth: Factual data, either the ideal correct response, or context used to respond (e.g. data retrieved from a vector DB)
Model Console
Navigate to the Model Console in the AutoEval dashboard, and click on the Faithfulness model.
Enter values for input, output and ground_truth, and click Run Model to calculate a score:

API
We provide a REST API surface as well as client SDKs in Python and Node.js. We recommend using the client SDKs for a streamlined experience.
For more information, see the API section.
First, let's install the requisite packages:
- pip
- npm
pip install lastmile
npm install lastmile
- python
- node.js
from lastmile.lib.auto_eval import AutoEval, BuiltinMetrics
import pandas as pd
client = AutoEval(api_token="api_token_if_LASTMILE_API_TOKEN_not_set")
query = "Where did the author grow up?"
expected_response = "England"
llm_response = "France"
eval_result = client.evaluate_data(
data=pd.DataFrame({
"input": [query],
"output": [llm_response],
"ground_truth": [expected_response]
}),
metrics=[BuiltinMetrics.FAITHFULNESS]
)
print(eval_result)
import { AutoEval, Metric, BuiltinMetrics } from "lastmile/lib/auto_eval";
const client = new AutoEval({ apiKey: "api_token_if_LASTMILE_API_TOKEN_not_set" });
const query = "Where did the author grow up?"
const expectedResponse = "England"
const llmResponse = "France"
const result = await client.evaluateData(
/*data*/ [
{
input: query,
output: llmResponse,
ground_truth: expectedResponse,
},
],
/*metrics*/ [BuiltinMetrics.FAITHFULNESS]
);
console.table(result);
You can reference any metric by its name as it appears in the Model Console. Accepted values include:
Metric(name="Faithfulness")Metric(name="Relevance")Metric(name="Summarization")Metric(name="Toxicity")Metric(name="Answer Correctness")
Congrats on running your first evaluation! The platform can do a lot more, so head on to these sections or guides below to continue your AutoEval journey.
Don't have app data handy? No problem - check out our Example Datasets to get synthetic datasets to try out the platform.
Create Datasets>
Upload and manage application data for running and training evals, and generate synthetic labels.
Synthetic Labeling>
Generate high-quality labels for your data using LLM Judge with human-in-the-loop to refine synthetic labels.
Fine-tune Models>
Use the AutoEval fine-tuning service to develop custom metrics for your application.
Run Evals>
Compute metrics by running high-performance inference using a prebuilt or fine-tuned model.
Getting Started Guide>
Start-to-finish overview of AutoEval, from running evals, labeling with LLM Judge to fine-tuning a custom metric.
RAG Evaluation>
Evaluate a RAG application for hallucination, relevance and other out-of-the-box metrics available via AutoEval.
Real-time guardrails>
Build real-time guardrails in a RAG application using fine-tuned alBERTa 🍁 models.