AutoEval
Platform Overview
The AutoEval fine-tuning platform enables the customization of alBERTa small language models (SLMs) to better evaluate and measure your application's performance.
It solves a key problem in generative AI application development -- helping you develop metrics that accurately represent your application's performance, enabling you to iteratively drive improvements and have confidence in production.
Here's how it works:
You come to AutoEval if you have a compound AI application, such as a RAG pipeline or agent system, and you want to understand if the application is performing well or not. This can be a single quality metric of AI interactions, or a whole suite of metrics - each measuring something specific about the system:
- Is the response faithful to the data provided?
- Is the input relevant to the application's purpose? (input guardrail)
- Does the response adhere to my company's brand tone?
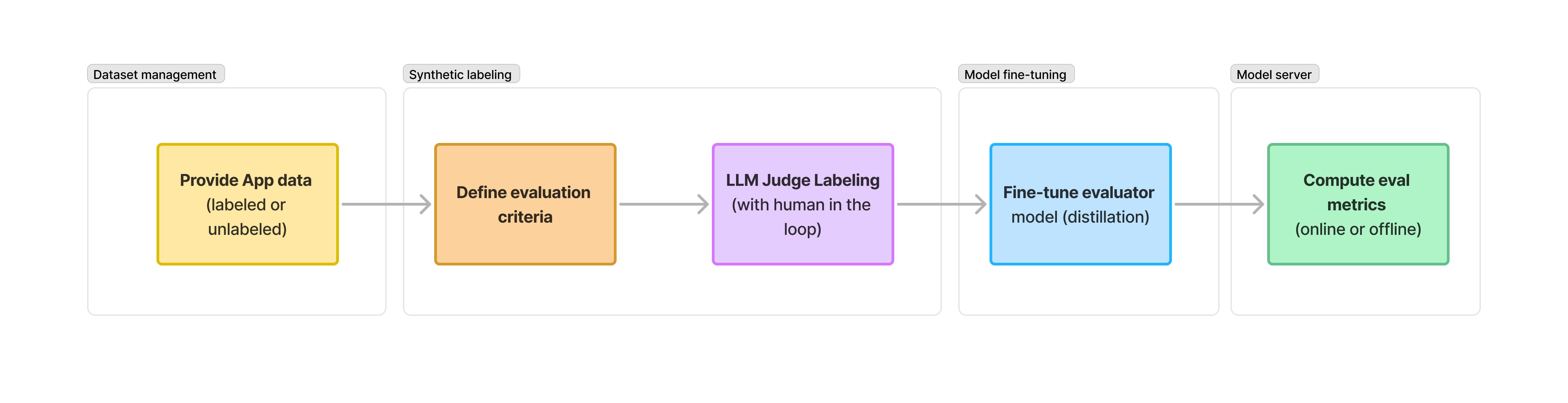
AutoEval starts from the application's trace datasets, labels the interactions using LLM Judge where you can specify an evaluation criteria in natural language (prompt), and then fine-tunes an alBERTa SLM to learn the distribution of those labeled interactions. You can then run the fine-tuned model as an eval, or at runtime as a guardrail. For e.g. if a response is deemed to have hallucinated, i.e. unsufficiently faithful to the data, then deny that response from reaching the user.
Platform Capabilities
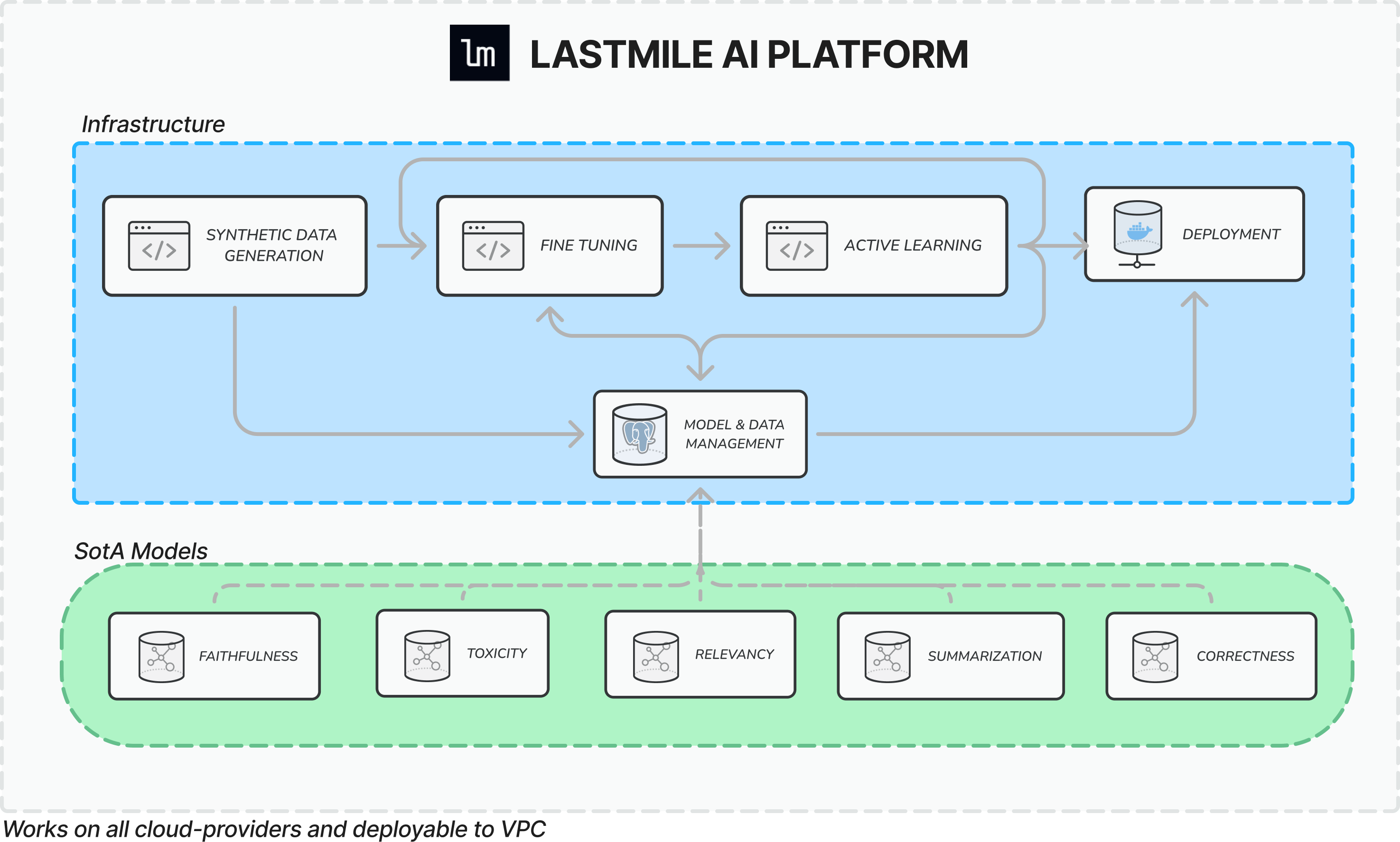
Out-of-the-box metrics
Key metrics to evaluate typical AI applications (such as RAG) are available out of the box. Detect hallucinations, measure input/context relevance, score summarizations and more. Learn more
Dataset Management
Store application trace data in AutoEval to be used for running evals, for labeling, and for fine-tuning evaluator models. Learn more
Synthetic Labeling (LLM Judge Labeling)
For use cases that have few to no labels or ground truth data, AutoEval provides the capability to synthetically generate labels. We refer to this as Synthetic Labeling. It uses an LLM to generate labels given a custom evaluation criteria, and also allows a developer to improve the labels manually as part of an refinement process (typically labeled by a subject matter expert).
You can continuously improve the label quality by providing additional samples of ground truth data.
Fine-tuning
Design your own eval metric. Fine-tuning allows you to improve the performance of LastMile AI's models by tuning the performance to your specific data and use case.
Online inference
You can use the evaluator models for offline tasks such as running evals, as well as online tasks such as guardrails. AutoEval has a high-performance inference server that can handle both kinds of workloads.
Use the quickstart guide to get started running your first evaluation.